4.2 Create Evaluation Script
1. Create Evaluation Script
Let's copy over the evaluate.py script into our application source folder.
- Make sure you are in the root directory of the repo.
- Then run this command:
| cp src.sample/api/evaluate.py src/api/.
|
2. Review Evaluation Workflow
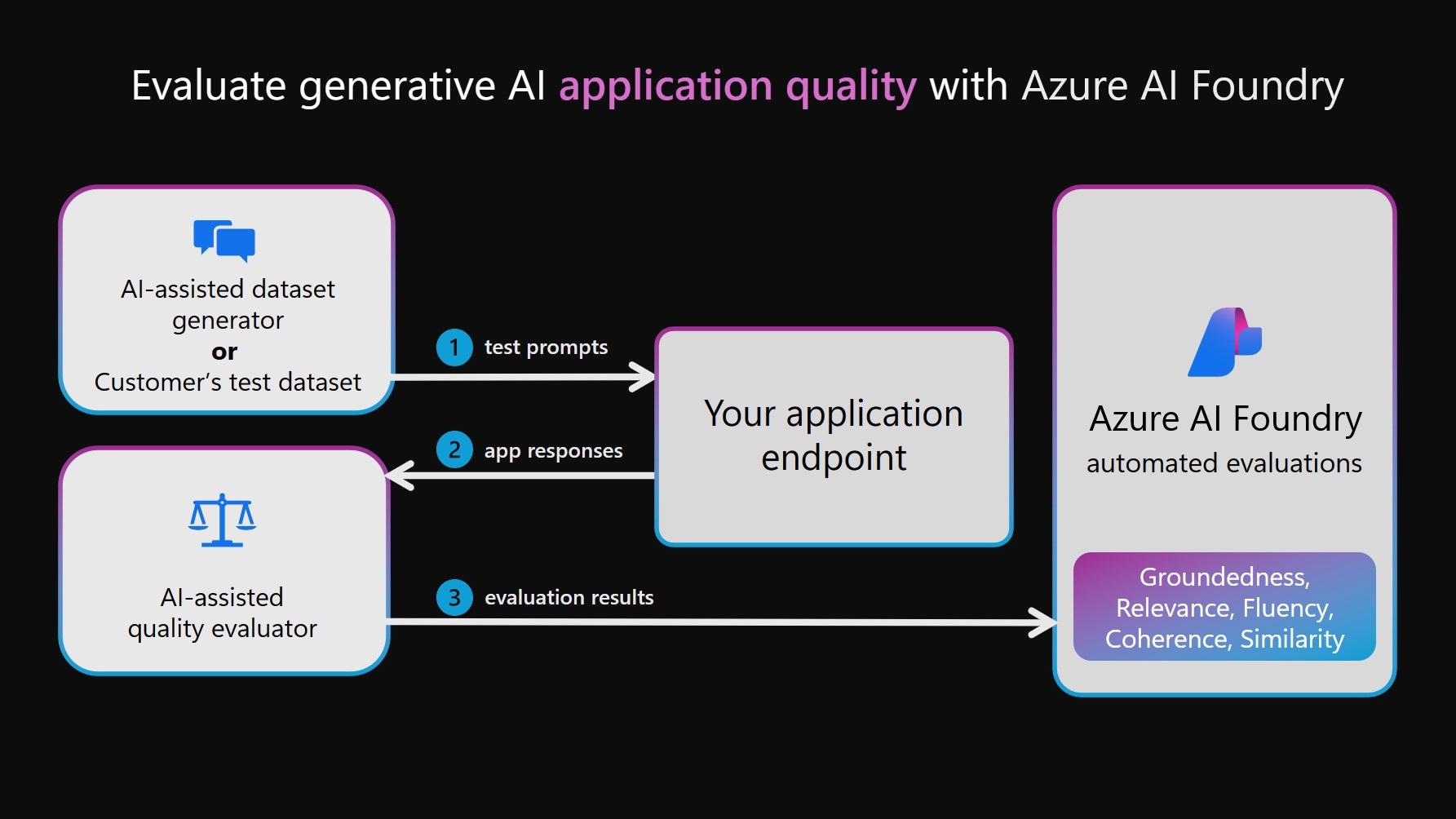
Let's review the workflow required for AI-Assisted evaluation:
- We have an evaluation test dataset containing query/truth pairs
- We have a target AI (applicationl) that will generate the responses
- We have a judge AI (evaluator) that will grade those responses
- The judge has scoring criteria they use to generate evaluation metrics
- The evaluation results are published locally, or to Azure AI Foundry
3. Unpack Evaluation Script
3.1 Create AI Project Client
| src/api/evaluate.py |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 | # ----------------------------------------------
# 1. Create AI Project Client
# ----------------------------------------------
import os
import pandas as pd
from azure.ai.projects import AIProjectClient
from azure.ai.projects.models import ConnectionType
from azure.ai.evaluation import evaluate, GroundednessEvaluator
from azure.identity import DefaultAzureCredential
from chat_with_products import chat_with_products
# load environment variables from the .env file at the root of this repo
from dotenv import load_dotenv
load_dotenv()
# create a project client using environment variables loaded from the .env file
project = AIProjectClient.from_connection_string(
conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential()
)
connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True)
|
3.2 Specify Model & Evaluators
| src/api/evaluate.py |
|---|
| # ----------------------------------------------
# 2. Define Evaluator Model to use
# ----------------------------------------------
evaluator_model = {
"azure_endpoint": connection.endpoint_url,
"azure_deployment": os.environ["EVALUATION_MODEL"],
"api_version": "2024-06-01",
"api_key": connection.key,
}
groundedness = GroundednessEvaluator(evaluator_model)
|
3.3 Create Evaluation Wrapper
| src/api/evaluate.py |
|---|
| # ----------------------------------------------
# 3. Create Eval Wrapper Function for Query
# ----------------------------------------------
def evaluate_chat_with_products(query):
response = chat_with_products(messages=[{"role": "user", "content": query}])
return {"response": response["message"].content, "context": response["context"]["grounding_data"]}
|
3.4 Run Evaluation & Print
This is the entry point for the evaluation script.
- It uses the evaluate function from the
azure.ai.evaluation package to run a built-in evaluator (GroundednessEvaluator) to score the responses from the target app.
- If both the data (test) and target (function) are provided, it will first invoke the target with that data - and then run evaluations on the results.
- If
azure_ai_project is set, then the evaluation results are also logged to Azure AI Foundry
| src/api/evaluate.py |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50 | # ----------------------------------------------
# 4. Run the Evaluation
# View Results Locally (Saved as JSON)
# Get Link to View Results in Foundry Portal
# NOTE:
# Evaluation takes more tokens
# Try to increase Rwate limit (Tokens per minute)
# Script should handle limit errors if needed
# ----------------------------------------------
# Evaluate must be called inside of __main__, not on import
if __name__ == "__main__":
from config import ASSET_PATH
# workaround for multiprocessing issue on linux
from pprint import pprint
from pathlib import Path
import multiprocessing
import contextlib
with contextlib.suppress(RuntimeError):
multiprocessing.set_start_method("spawn", force=True)
# run evaluation with a dataset and target function,
# log to the project
result = evaluate(
data=Path(ASSET_PATH) / "chat_eval_data.jsonl",
target=evaluate_chat_with_products,
evaluation_name="evaluate_chat_with_products",
evaluators={
"groundedness": groundedness,
},
evaluator_config={
"default": {
"query": {"${data.query}"},
"response": {"${target.response}"},
"context": {"${target.context}"},
}
},
azure_ai_project=project.scope,
output_path="./myevalresults.json",
)
tabular_result = pd.DataFrame(result.get("rows"))
pprint("-----Summarized Metrics-----")
pprint(result["metrics"])
pprint("-----Tabular Result-----")
pprint(tabular_result)
pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
|