4.1 Create Evaluation Dataset¶
This begins Part 3 of the tutorial. This stage is completed USING THE AZURE AI FOUNDRY SDK.
At the end of this section, you should have established an evaluation inputs dataset, created an evaluation script for AI-assisted evaluation, and run the script to assess the chat AI app for quality. You will then learn to explore the evaluation outcomes locally, and via the Azure AI Foundry portal, and understand how to customize and automate the process for rapid iteration and improvement of your application quality.
1. Evaluating Generative AI Apps¶
The evaluation phase is critical to assessing the quality and safety of your generative AI application. The Azure AI Foundry provides a comprehensive set of tools and guidance to support evaluation in three dimensions. Learn More Here.
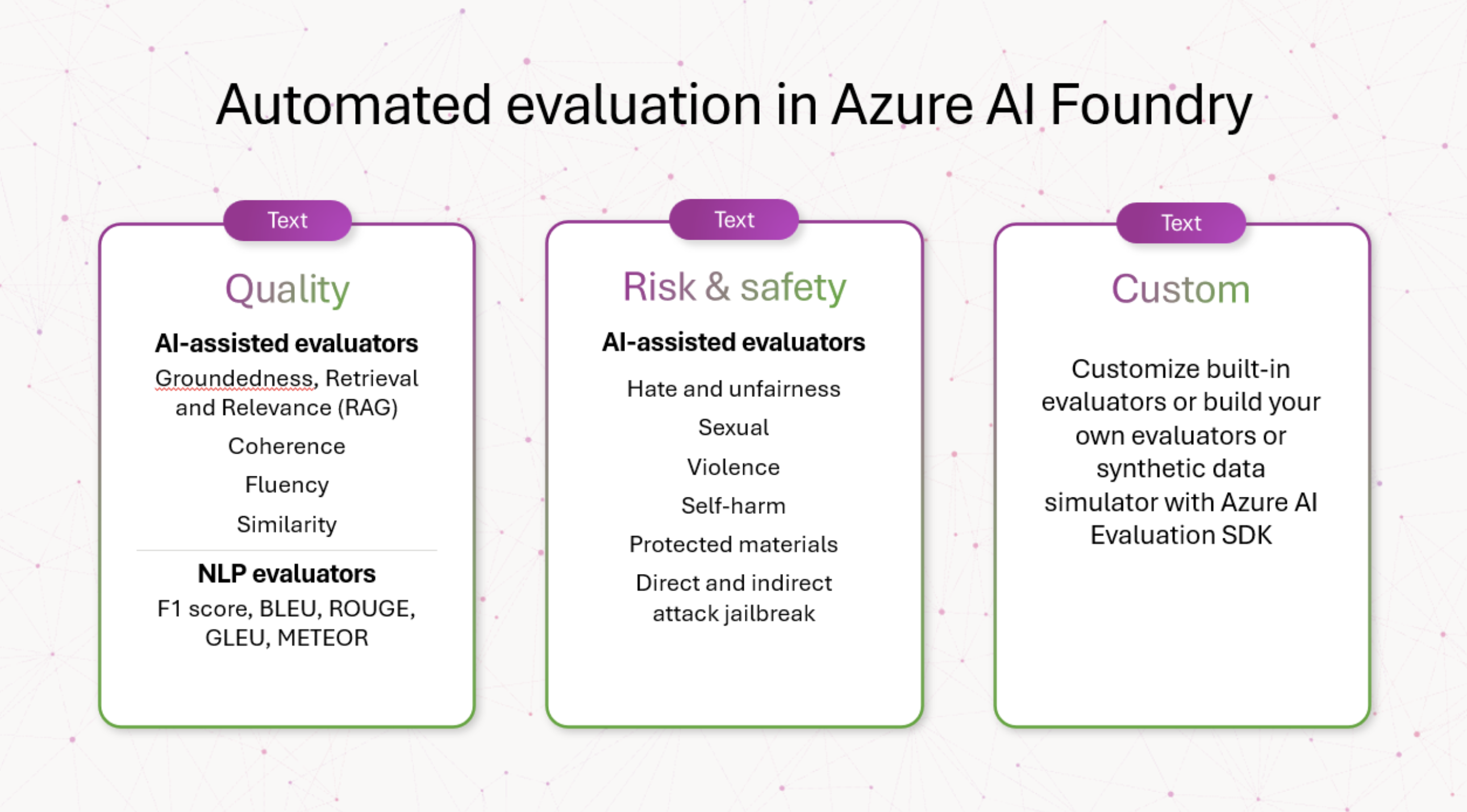
- Risk and safety evaluators: Evaluating potential risks associated with AI-generated content. Ex: evaluating AI predisposition towards generating harmful or inappropriate content.
- Performance and quality evaluators: Assessing accuracy, groundedness, and relevance of generated content using robust AI-assisted and Natural Language Processing (NLP) metrics.
- Custom evaluators: Tailored evaluation metrics that allow for more detailed and specific analyses. Ex: addressing app-specific requirements not covered by standard metrics.
AI-Assisted Evaluators are available only in select regions (Recommended: East US 2)
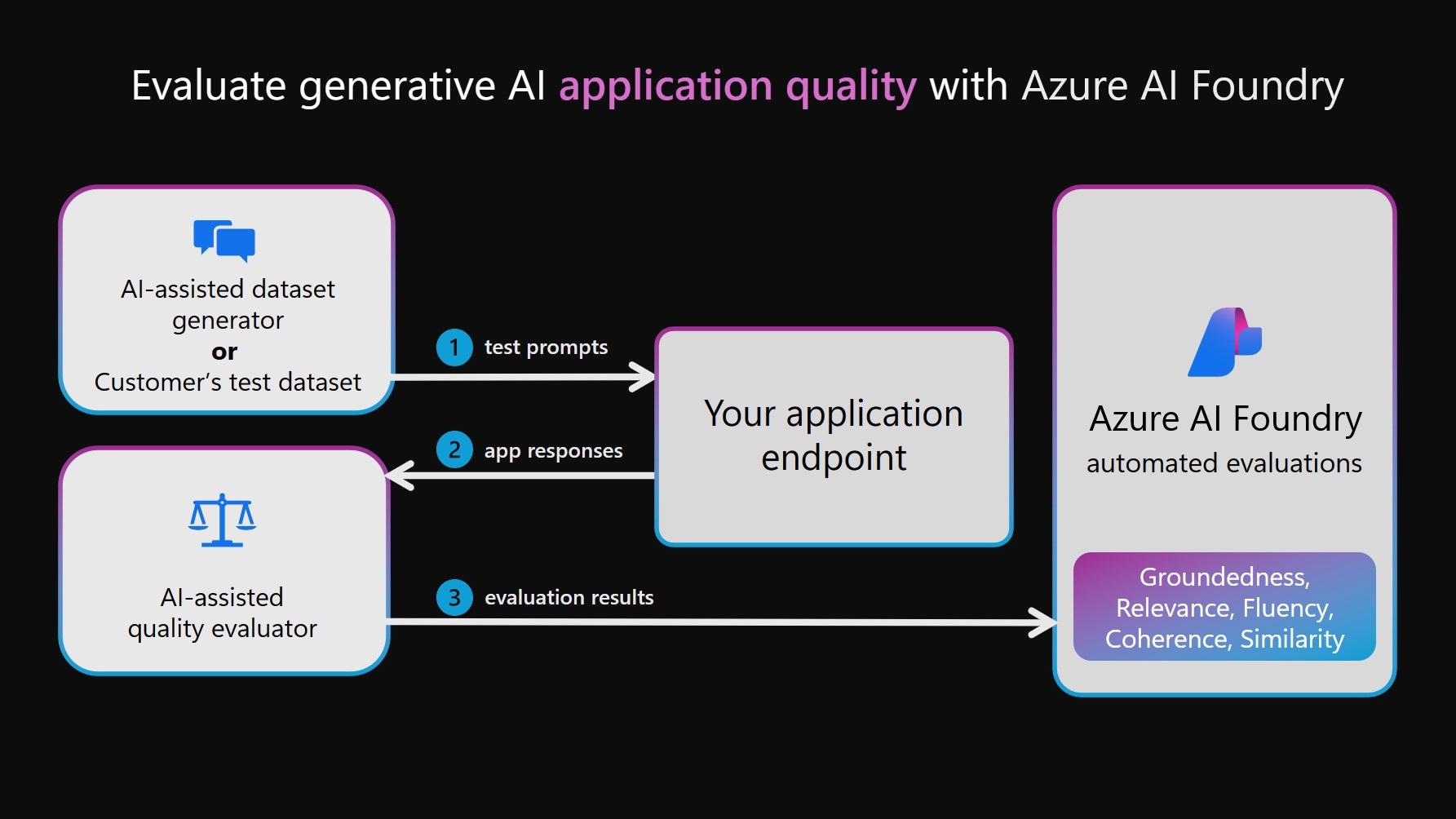
2. AI-Assisted Evaluation Flow¶
So far, we've tested the chat application interactively (command-line) using a single test prompt. Now, we want to evaluate the responses on a larger and more diverse set of test prompts including edge cases. We can then use those results to iterate on our application (e.g., prompt template, data sources) till evaluations pass our acceptance criteria.
To do this we use AI-Assisted Evaluation - also referred to as LLM-as-a-judge - where we ask a second AI model ("judge") to grade the responses of the first AI model ("target"). The workflow is as shown below:
- First, create an evaluation dataset that consists of diverse queries for testing.
- Next, have the target AI (app) generate responses for each query
- Next, have the judge AI (assessor) grade tge {query, response} pairs
- Finally, visualize results (individual vs. aggregate metrics) for review.
3. Create Evaluation Dataset¶
Let's copy over the chat_eval_data.jsonl dataset into our assets folder.
- Make sure you are in the root directory of the repo.
- Then run this command:
1 | |
4. Review Evaluation Dataset¶
The Azure AI Foundry supports different data formats for evaluation including:
- Query/Response - each result has the query, response, and ground truth.
- Conversation (single/multi-turn) - messages (with content, role, optional context)
Click to expand and view the evaluation dataset
| src/api/assets/chat_eval_data.jsonl | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Our dataset reflects the first format, where the test prompts contain a query with the ground truth for evaluating responses. The chat AI will then generate a response (based on query) that gets added to this record, to create the evaluation dataset that is sent to the "judge" AI.
1 2 3 4 | |